
Работа с базами данных в С++

|

Базы данных
Автор темы:
nsg
, дек 17 2009 07:49
4 ответов в этой теме
#1

nsg
-
- Пользователи ST test (off)
-

- 105 сообщений
живет тут
Опубликовано 17 Декабрь 2009 - 07:49
ICQ 296461926

#2
nsg
-
- Пользователи ST test (off)
-
- 105 сообщений
живет тут
Опубликовано 26 Февраль 2010 - 10:20
Краткая история баз данных
В табл. 1 сведена история развития технологии баз данных. До середины 1960-х годов почти все компьютерные хранилища данных были на магнитных лентах. Поскольку лента может обрабатываться только последовательно, данные должны были храниться в виде списков (или последовательных файлов, как они назывались). Однако, как вы узнали в начале этой главы, хранение даже простейших данных в таком формате чревато большими проблемами.
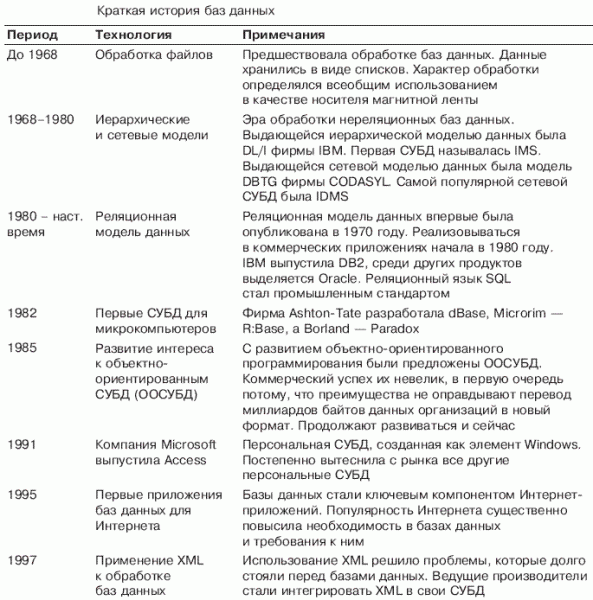
Таблица 1
Ранние модели баз данных
С коммерческим успехом хранилищ на дисках в середине 1960-х стало возможным получение непоследовательного, или прямого, доступа к записям. Базы данных стали разрабатываться по-другому. Изначально стали успешными две конкурирующие архитектуры, или модели. Корпорация IBM разработала и внедрила DL/I (Data Language One, язык данных один), который моделировал данные в базах данных в форме иерархий, или деревьев (см. рис. 1.а). Эта модель, которая была разработана совместно с промышленными предприятиями, легко могла использоваться для поддержки данных, таких как сметы материалов и списки деталей, но для общих целей мало подходила. Представление неиерархических сетевых данных (рис. 1.б) было громоздким.
После этого CODASYL, группа, которая разрабатывала стандарты для языка COBOL, в 1970 году создала модель под названием DBTG (Data Base Task Group, группа задач баз данных). Модель DBTG была готова к представлению как иерархических, так и сетевых данных. Один раз эта модель предлагалась в качестве национального стандарта, но не была принята в первую очередь из-за своей сложности. Однако это была основа для ряда коммерчески успешных СУБД в семидесятых и восьмидесятых годах прошлого века. Наиболее успешным был продукт корпорации Cullinane под названием IDMS.
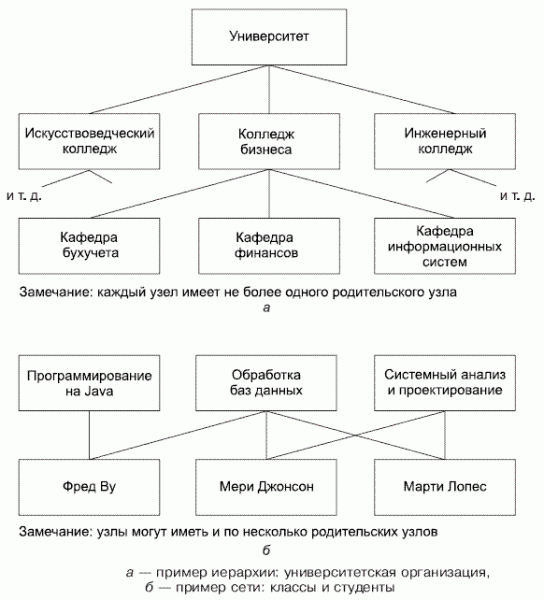
Рисунок 1
Реляционная модель
Реляционная модель, которая впервые была предложена Е. Ф. Коддом в 1970 году. Кодд работал в IBM, и после десяти лет исследований, разработки и лоббирования на уровне корпорации он с коллегами убедил IBM разработать несколько СУБД, основанных на реляционной модели. Наиболее известным из этих продуктов является DB2 — СУБД, которая активно используется и поныне.
Между тем другие корпорации (такие как Oracle, Ingres, Sybase и Informix) тоже разработали СУБД, основанные на реляционной модели. SQL Server был разработан в Sybase и в конце восьмидесятых годов продан Microsoft. Сегодня DB2, Oracle и SQL Server являются наиболее выдающимися коммерческими СУБД.
В табл. 1 сведена история развития технологии баз данных. До середины 1960-х годов почти все компьютерные хранилища данных были на магнитных лентах. Поскольку лента может обрабатываться только последовательно, данные должны были храниться в виде списков (или последовательных файлов, как они назывались). Однако, как вы узнали в начале этой главы, хранение даже простейших данных в таком формате чревато большими проблемами.
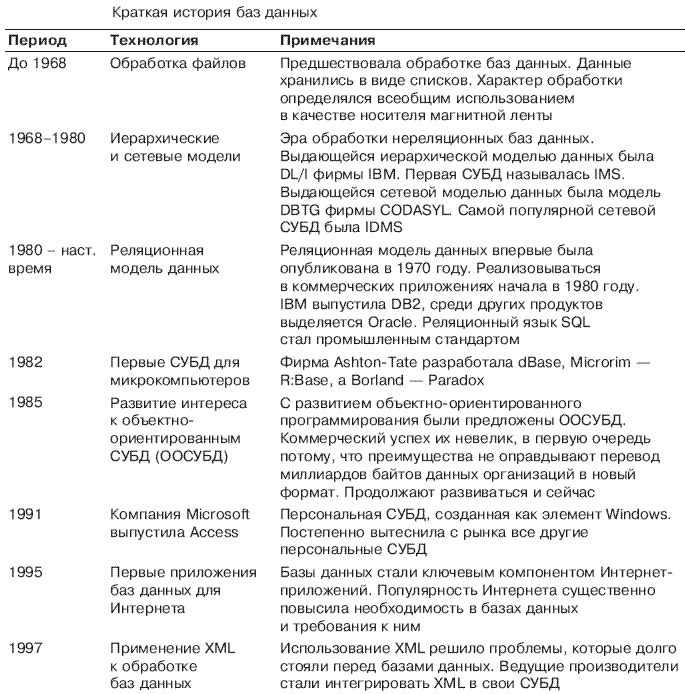
Таблица 1
Ранние модели баз данных
С коммерческим успехом хранилищ на дисках в середине 1960-х стало возможным получение непоследовательного, или прямого, доступа к записям. Базы данных стали разрабатываться по-другому. Изначально стали успешными две конкурирующие архитектуры, или модели. Корпорация IBM разработала и внедрила DL/I (Data Language One, язык данных один), который моделировал данные в базах данных в форме иерархий, или деревьев (см. рис. 1.а). Эта модель, которая была разработана совместно с промышленными предприятиями, легко могла использоваться для поддержки данных, таких как сметы материалов и списки деталей, но для общих целей мало подходила. Представление неиерархических сетевых данных (рис. 1.б) было громоздким.
После этого CODASYL, группа, которая разрабатывала стандарты для языка COBOL, в 1970 году создала модель под названием DBTG (Data Base Task Group, группа задач баз данных). Модель DBTG была готова к представлению как иерархических, так и сетевых данных. Один раз эта модель предлагалась в качестве национального стандарта, но не была принята в первую очередь из-за своей сложности. Однако это была основа для ряда коммерчески успешных СУБД в семидесятых и восьмидесятых годах прошлого века. Наиболее успешным был продукт корпорации Cullinane под названием IDMS.
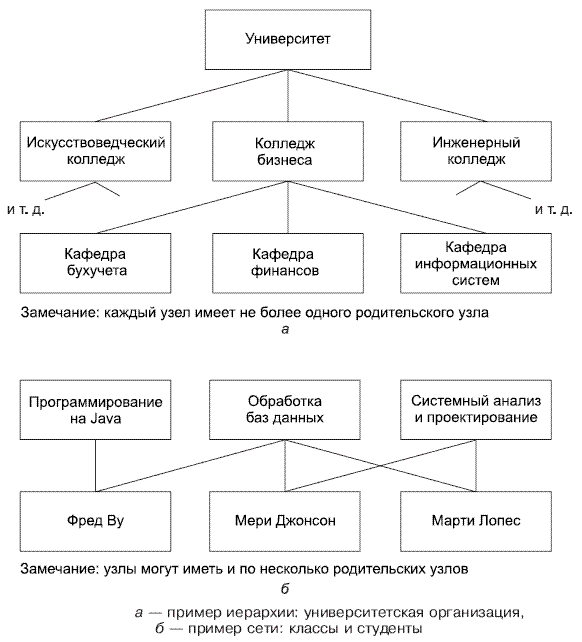
Рисунок 1
Реляционная модель
Реляционная модель, которая впервые была предложена Е. Ф. Коддом в 1970 году. Кодд работал в IBM, и после десяти лет исследований, разработки и лоббирования на уровне корпорации он с коллегами убедил IBM разработать несколько СУБД, основанных на реляционной модели. Наиболее известным из этих продуктов является DB2 — СУБД, которая активно используется и поныне.
Между тем другие корпорации (такие как Oracle, Ingres, Sybase и Informix) тоже разработали СУБД, основанные на реляционной модели. SQL Server был разработан в Sybase и в конце восьмидесятых годов продан Microsoft. Сегодня DB2, Oracle и SQL Server являются наиболее выдающимися коммерческими СУБД.
ICQ 296461926
#3
nsg
-
- Пользователи ST test (off)
-
- 105 сообщений
живет тут
Опубликовано 26 Февраль 2010 - 10:39
Краткая история баз данных (Продолжение)
СУБД для персональных компьютеров
С появлением большого числа микрокомпьютеров стало возможно иметь персональные базы данных. В результате был разработан ряд СУБД для персональных компьютеров. Наиболее успешной из них была dBase — продукт корпорации Ashton-Tate. Еще среди ранних персональных СУБД можно назвать R:base корпорации Microrim и Paradox от Borland.
Поскольку компьютеры обладали довольно большой вычислительной мощностью, персональные СУБД предоставляли больше графических интерфейсов пользователя. Кроме того, со временем под влиянием этих продуктов изменились и интерфейсы больших организационных СУБД. На рис. 2 показан этот момент. Технология того, что показано на рис. 2(а), разрабатывалась для символьноориентированных интерфейсов, которые были распространены для СУБД, предшествовавших персональным компьютерам. На рис. 2(б) показан пример графического интерфейса, который появился с возникновением персональных СУБД.

Рисунок 2
Объектно-ориентированные СУБД
Объектно-ориентированное программирование начало развиваться в середине восьмидесятых годов прошлого века и привело к созданию объектно-ориентированных СУБД. Целью этих продуктов была способность хранить объекты из объектно-ориентированного программирования (например, из языков С++ или Java) в базе данных, не преобразуя их в реляционный формат.
В настоящее время ООСУБД не имеют коммерческого успеха. Их использование требует от организаций преобразовывать свои базы данных из реляционного в ООСУБД-формат. Кроме того, большинство крупных организаций имеют более старые приложения, не основанные на объектно-ориентированном программировании. Программы в таких приложениях потребовалось бы как-то сопровождать новыми ООСУБД. Таким образом, высокая стоимость перевода существующих баз данных и информационных систем из реляционных СУБД в ООСУБД задерживает их широкое распространение.
Были разработаны объектно-ориентированные СУБД, такие как Oracle 8i и 9i, что позволило создавать как реляционное, так и объектное представление данных одной и той же базы данных. Эти СУБД начинают получать коммерческий успех, но не такой, как чисто реляционные СУБД.
Недавняя история
В 1991 году Microsoft выпустила Access, который на несколько лет вытеснил с рынка все остальные СУБД. Частично это произошло благодаря тому, что Access был интегрирован в Microsoft Office, и Microsoft смогла использовать свое влияние на рынке и монополию в связи с Windows для смещения других продуктов. Правда, Microsoft нужно отдать справедливость: Access — суперпродукт. Он доминирует на рынке, потому что это легкая в использовании и сильная СУБД.
Как все знают, использование Интернета распространилось в середине девяностых годов. Но немногие знают, что именно это сильно повысило значение и важность технологии баз данных. Как только ранние статические веб-страницы уступили дорогу динамическим, как только стали иметь успех компании типа Amazon.com и как только большие организации начали использовать Интернет для публикации своих данных, все большее и большее количество сайтов стало зависеть от баз данных. Эта тенденция продолжается и по сей день.
Наконец, в последние годы появился и стал широко использоваться язык XML, который представляет собой технологию для поддержки веб-сайтов, но был расширен для проведения важных решений, связанных с базами данных. Интеграция технологии баз данных с XML является ведущим пунктом области баз данных сегодня и будет важна еще много лет в будущем.
Заключение
Хотя обработка баз данных всегда была важной темой, популярность Интернета сделала ее еще и одной из самых нужных специальностей. Цель базы данных — помочь людям и организациям вести учет различных вещей. Хотя для этой цели можно использовать списки, они вызывают множество проблем. Их сложно изменять без возникновения несоответствий, удаления из списков могут иметь непредвиденные последствия, а неполные данные трудно записывать. Кроме того, вводя данные, легко вызвать их противоречивость. Наконец, различные части организации хотят поддерживать некоторые данные совместно, а некоторые — исключительным образом. Это трудно организовать при использовании списков.
Базы данных состоят из групп реляционных таблиц. В большинстве случаев каждая таблица содержит данные по определенной теме. Поддержка данных таким образом решает все проблемы, перечисленные для списков. Связи в таблицах представляются разными способами. Таблицы можно создавать с помощью языка SQL, который является промышленным стандартом для обработки таблиц.
Система базы данных состоит из четырех основных элементов: пользователи, приложения базы данных, СУБД и сама база данных. Пользователи применяют базу данных для решения своих задач. Приложения производят формы, запросы и отчеты, выполняют логику приложения и управляют обработкой базы. СУБД создает, обрабатывает и администрирует базу данных. База данных — это самодокументированное собрание интегрированных записей. Она содержит пользовательские данные, метаданные, индексы, хранимые процедуры, триггеры и метаданные приложения. Хранимая процедура — это программа, которая обрабатывает участок базы данных и хранится в базе данных. Триггер — это процедура, которая вызывается при наступлении определенного события. На рис. 3 показаны функции компонентов базы данных.
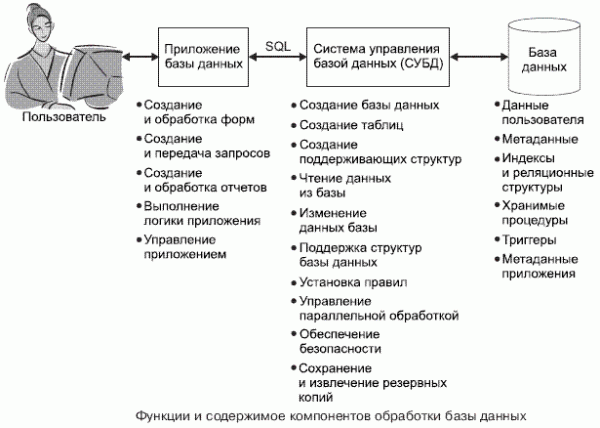
Рисунок 3
Технология баз данных может использоваться в широком спектре приложений. Некоторые базы данных используются одним человеком, другие — группой людей, а третьи — большими организациями.
Подобно всем информационным системам, системы баз данных разрабатываются в течение трех фаз: формулирования требований, проектирования и реализации. Во время фазы формулирования требований разрабатывается модель данных, или логическое представление структуры базы данных. Модели данных важны, потому что от них зависит проектирование базы данных и приложения. Диаграмма сущность—связь — средство, используемое для представления модели данных.
Модель данных преобразуется в таблицы и связи на фазе проектирования. Также проектируются индексы, ограничения, хранимые процедуры и триггеры. Диаграммы структур данных иногда используются для таблиц документов и их связей. Во время фазы реализации создаются таблицы, связи и ограничения, пишутся хранимые процедуры и триггеры, база данных заполняется данными и тестируется. Сегодня таблицы и связанные с ними конструкции создаются с помощью SQL или графических средств, являющихся частью СУБД.
СУБД для персональных компьютеров
С появлением большого числа микрокомпьютеров стало возможно иметь персональные базы данных. В результате был разработан ряд СУБД для персональных компьютеров. Наиболее успешной из них была dBase — продукт корпорации Ashton-Tate. Еще среди ранних персональных СУБД можно назвать R:base корпорации Microrim и Paradox от Borland.
Поскольку компьютеры обладали довольно большой вычислительной мощностью, персональные СУБД предоставляли больше графических интерфейсов пользователя. Кроме того, со временем под влиянием этих продуктов изменились и интерфейсы больших организационных СУБД. На рис. 2 показан этот момент. Технология того, что показано на рис. 2(а), разрабатывалась для символьноориентированных интерфейсов, которые были распространены для СУБД, предшествовавших персональным компьютерам. На рис. 2(б) показан пример графического интерфейса, который появился с возникновением персональных СУБД.

Рисунок 2
Объектно-ориентированные СУБД
Объектно-ориентированное программирование начало развиваться в середине восьмидесятых годов прошлого века и привело к созданию объектно-ориентированных СУБД. Целью этих продуктов была способность хранить объекты из объектно-ориентированного программирования (например, из языков С++ или Java) в базе данных, не преобразуя их в реляционный формат.
В настоящее время ООСУБД не имеют коммерческого успеха. Их использование требует от организаций преобразовывать свои базы данных из реляционного в ООСУБД-формат. Кроме того, большинство крупных организаций имеют более старые приложения, не основанные на объектно-ориентированном программировании. Программы в таких приложениях потребовалось бы как-то сопровождать новыми ООСУБД. Таким образом, высокая стоимость перевода существующих баз данных и информационных систем из реляционных СУБД в ООСУБД задерживает их широкое распространение.
Были разработаны объектно-ориентированные СУБД, такие как Oracle 8i и 9i, что позволило создавать как реляционное, так и объектное представление данных одной и той же базы данных. Эти СУБД начинают получать коммерческий успех, но не такой, как чисто реляционные СУБД.
Недавняя история
В 1991 году Microsoft выпустила Access, который на несколько лет вытеснил с рынка все остальные СУБД. Частично это произошло благодаря тому, что Access был интегрирован в Microsoft Office, и Microsoft смогла использовать свое влияние на рынке и монополию в связи с Windows для смещения других продуктов. Правда, Microsoft нужно отдать справедливость: Access — суперпродукт. Он доминирует на рынке, потому что это легкая в использовании и сильная СУБД.
Как все знают, использование Интернета распространилось в середине девяностых годов. Но немногие знают, что именно это сильно повысило значение и важность технологии баз данных. Как только ранние статические веб-страницы уступили дорогу динамическим, как только стали иметь успех компании типа Amazon.com и как только большие организации начали использовать Интернет для публикации своих данных, все большее и большее количество сайтов стало зависеть от баз данных. Эта тенденция продолжается и по сей день.
Наконец, в последние годы появился и стал широко использоваться язык XML, который представляет собой технологию для поддержки веб-сайтов, но был расширен для проведения важных решений, связанных с базами данных. Интеграция технологии баз данных с XML является ведущим пунктом области баз данных сегодня и будет важна еще много лет в будущем.
Заключение
Хотя обработка баз данных всегда была важной темой, популярность Интернета сделала ее еще и одной из самых нужных специальностей. Цель базы данных — помочь людям и организациям вести учет различных вещей. Хотя для этой цели можно использовать списки, они вызывают множество проблем. Их сложно изменять без возникновения несоответствий, удаления из списков могут иметь непредвиденные последствия, а неполные данные трудно записывать. Кроме того, вводя данные, легко вызвать их противоречивость. Наконец, различные части организации хотят поддерживать некоторые данные совместно, а некоторые — исключительным образом. Это трудно организовать при использовании списков.
Базы данных состоят из групп реляционных таблиц. В большинстве случаев каждая таблица содержит данные по определенной теме. Поддержка данных таким образом решает все проблемы, перечисленные для списков. Связи в таблицах представляются разными способами. Таблицы можно создавать с помощью языка SQL, который является промышленным стандартом для обработки таблиц.
Система базы данных состоит из четырех основных элементов: пользователи, приложения базы данных, СУБД и сама база данных. Пользователи применяют базу данных для решения своих задач. Приложения производят формы, запросы и отчеты, выполняют логику приложения и управляют обработкой базы. СУБД создает, обрабатывает и администрирует базу данных. База данных — это самодокументированное собрание интегрированных записей. Она содержит пользовательские данные, метаданные, индексы, хранимые процедуры, триггеры и метаданные приложения. Хранимая процедура — это программа, которая обрабатывает участок базы данных и хранится в базе данных. Триггер — это процедура, которая вызывается при наступлении определенного события. На рис. 3 показаны функции компонентов базы данных.

Рисунок 3
Технология баз данных может использоваться в широком спектре приложений. Некоторые базы данных используются одним человеком, другие — группой людей, а третьи — большими организациями.
Подобно всем информационным системам, системы баз данных разрабатываются в течение трех фаз: формулирования требований, проектирования и реализации. Во время фазы формулирования требований разрабатывается модель данных, или логическое представление структуры базы данных. Модели данных важны, потому что от них зависит проектирование базы данных и приложения. Диаграмма сущность—связь — средство, используемое для представления модели данных.
Модель данных преобразуется в таблицы и связи на фазе проектирования. Также проектируются индексы, ограничения, хранимые процедуры и триггеры. Диаграммы структур данных иногда используются для таблиц документов и их связей. Во время фазы реализации создаются таблицы, связи и ограничения, пишутся хранимые процедуры и триггеры, база данных заполняется данными и тестируется. Сегодня таблицы и связанные с ними конструкции создаются с помощью SQL или графических средств, являющихся частью СУБД.
ICQ 296461926
#4
Mr.Bags
-

- Пользователи ST test (off)
-
- 142 сообщений
живет тут
Опубликовано 26 Февраль 2010 - 07:08
C++ Builder и ADO
Краткое руководство о том как использовать базы Аccess через технологию ADO в С++ Builder.
Первое что нужно сделать это файл будущей базы в MS Access назовем его test.mdb
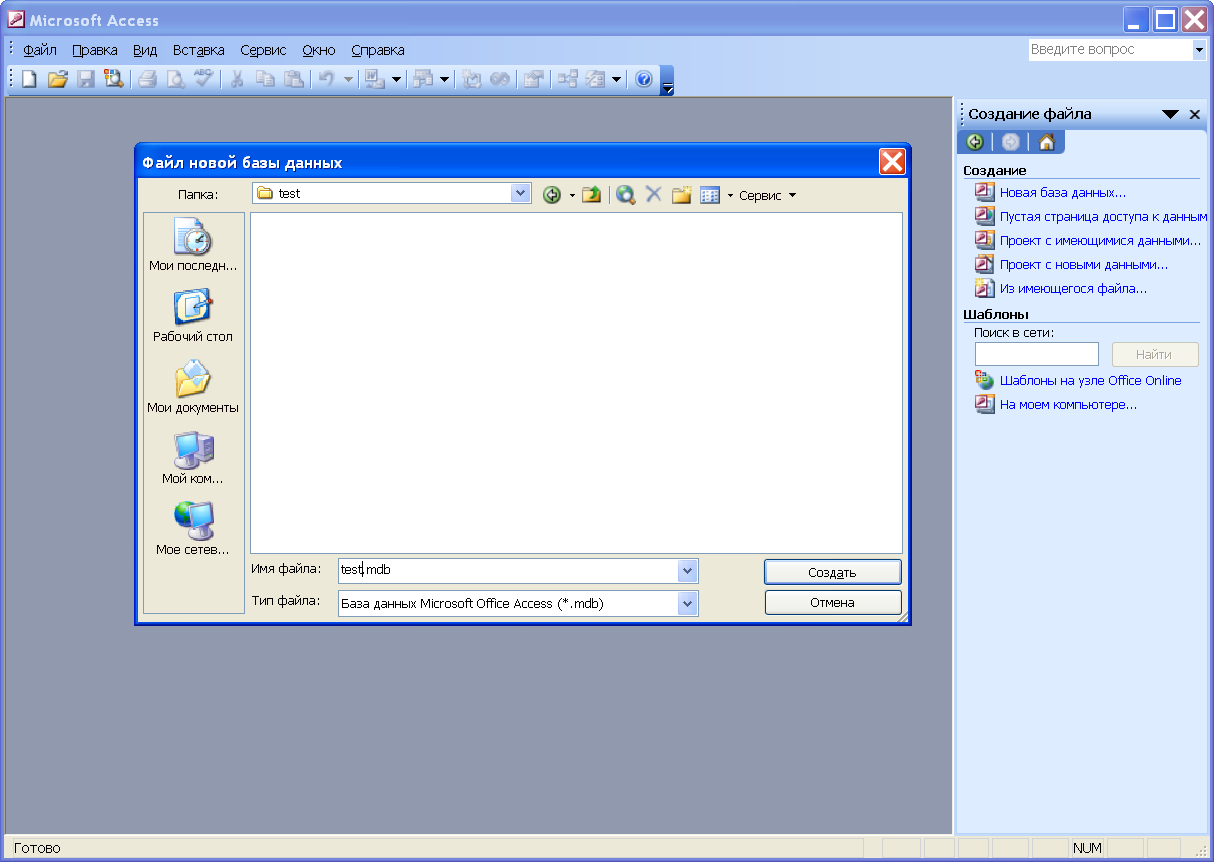
Далее в режиме конструктора создать там таблицу
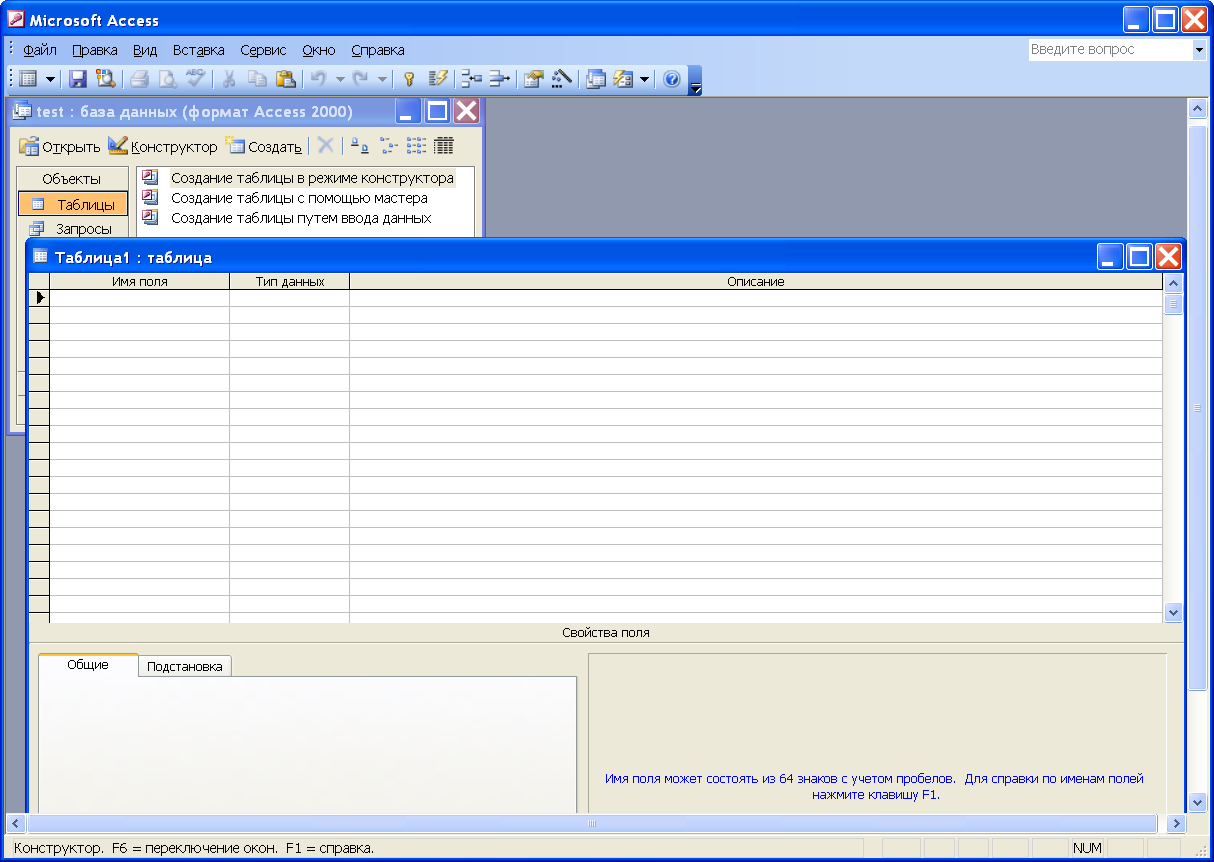
создать необходимые толбцы таблици определить их тип и заполнить необходимые параметры
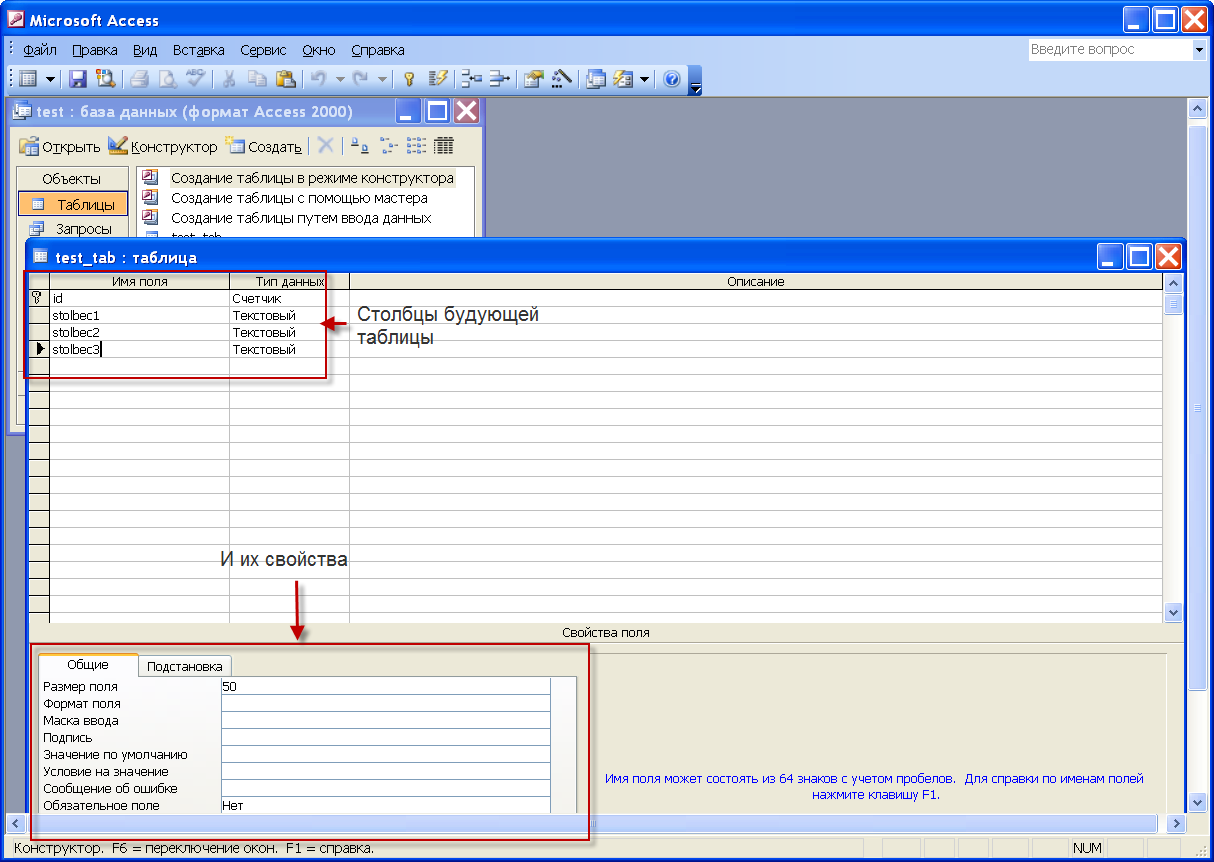
на этом этапе работа в акцесе закончена. Если нужно будет позже поменять структуру таблиц либо создать новые то мы снова вернемся к редактированию test.mdb открыв его в MS Access
Далее Запускаем C++ Builder
Первое что мы делаем это сохраняем проект в туже папку где и наш файл test.mdb
Далее в верхней части интегрированной среды разработки находятся вкладки с компонентами.

Для работы с акцесовской базой нам потребуются следующие компоненты:
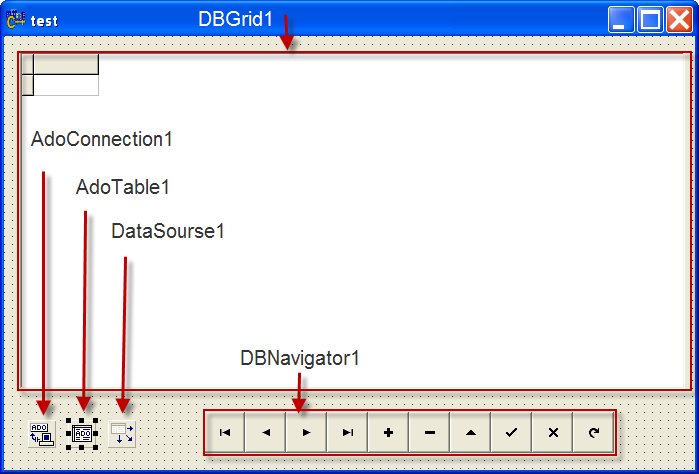
1) ADOConnection1 вкладка ADO - данный компонент содержит настройки подключения к БД
2) ADOTable1 вкладка ADO - компонент для операций с содержимым таблиц БД
3) DataSource1 - вкладка Data Access вспомогательный компонент - служит посредником между компонентами для оперирования с данными например ADOTable1 и компонентами для их отображения со вкладки DATA Controls
4) DBGrid1 - вкладка DATA Controls компонент для отображения содержимого таблиц БД
5) DBNavigator1 -вкладка DATA Controls компонент содержит необходимый набор кнопок для навигации по таблице, а таке для добавления, редактирования и удаления записей в таблице.
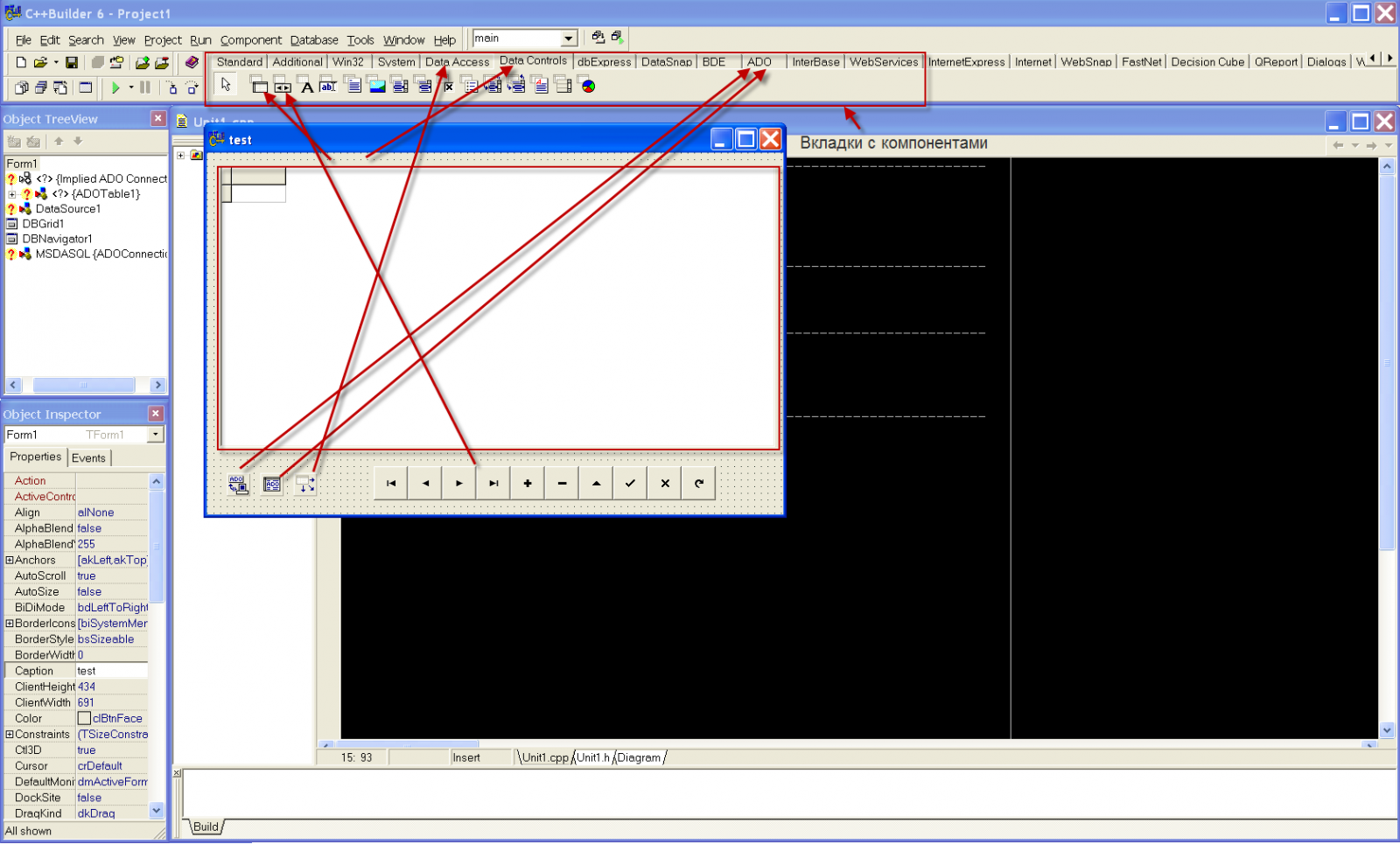
когда все компоненты на форме перейдем заполнению их параметров.
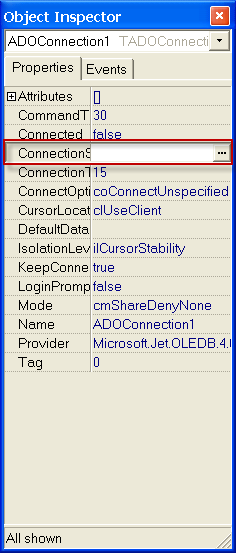
1) Нужно настроить компонент ADOConnection1, а именно параметр ConnectionString . Для это жмем на кнопку построения строки подключения
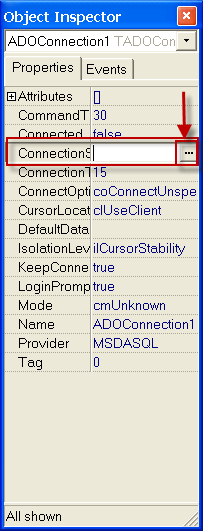
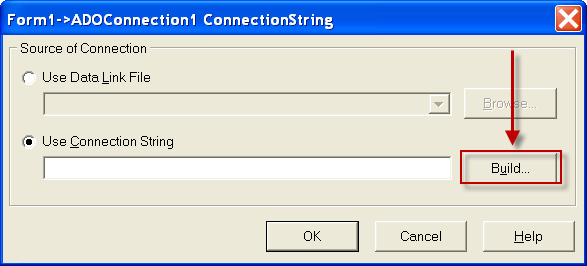
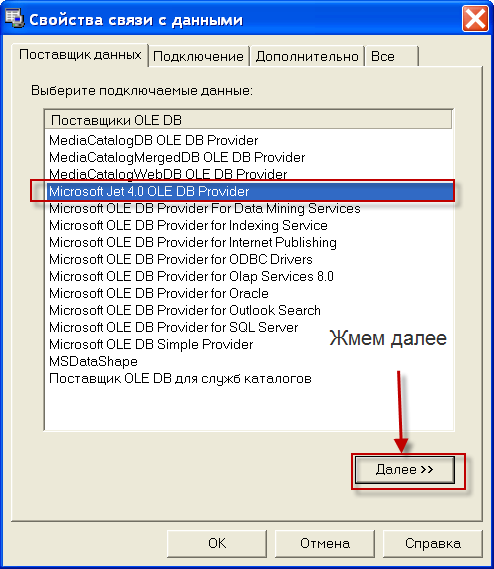
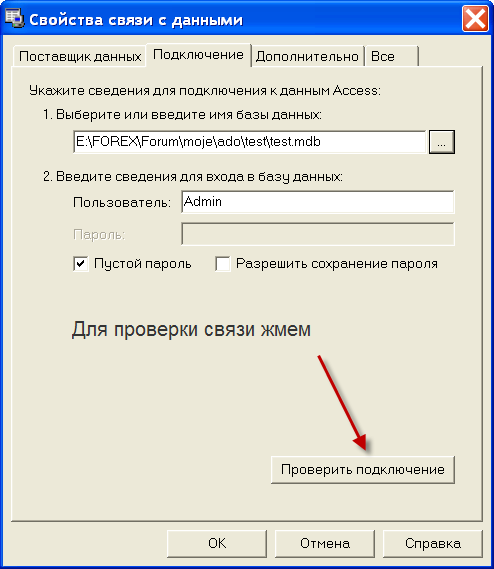
Если все ОК. то нажимаем кнопку внизу ОК. если нет то скорее всего нужно посмотреть установлен ли MS Access так как для нормальной работы приложению необходимы его модули. рекомендуется акцесс не ниже 2000.
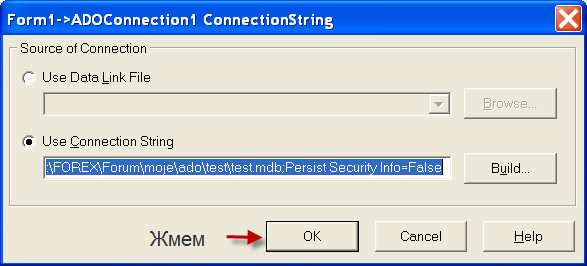
параметр LoginPromt установить в false что ба каждый раз при первом подключении к БД небыло запроса пароля. Если просит то login: Admin, пароль не заполнять и жмем ОК.
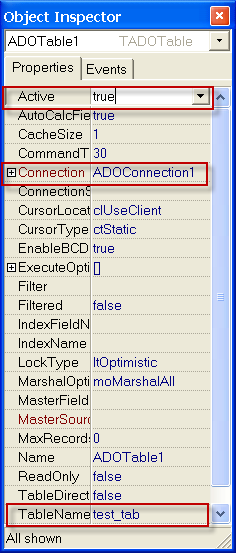
Далее нужно настроить компонент ADOTable1
в нем нужно настроить 3 параметра
1)Красное поле Connection - нужно выбрать ADOConnection1
2)TableName - указать название таблицы из БД - test_tab
3)Вверху параметр Active - выбрать true- параметр включения компонента
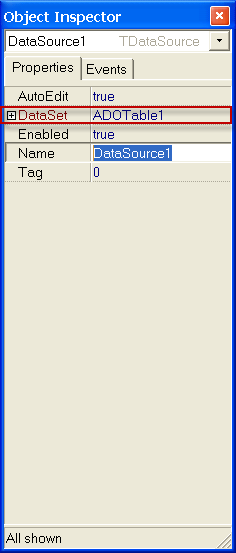
Далее нужно настроить компонент DataSource1
нужно указать параметр DataSet ADOTable1
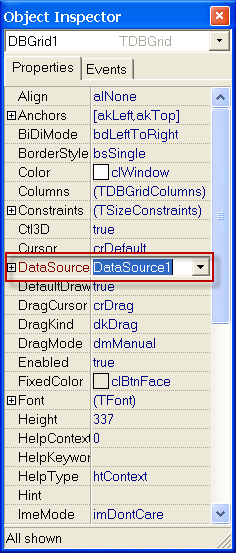
Далее в компонентах DBNavigator1 и DBGrid1 красное поле DataSourse выставить DataSource1
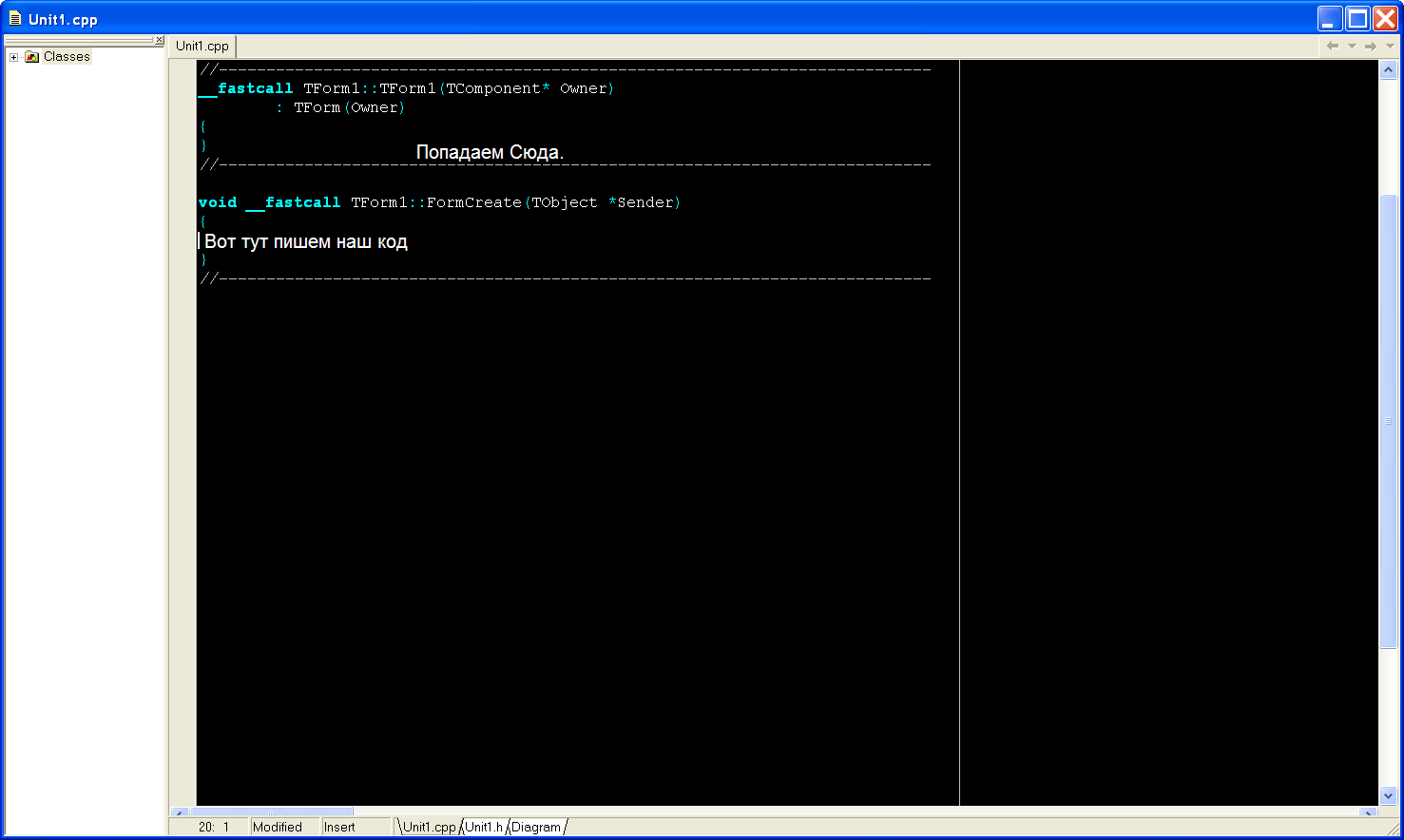
Последний штрих. для того что бы данное приложение работало на другом компьютере или при переносе в другую папку нужно сделать что бы строка подключения в компоненте ADOConnection1 вормировалась в момент запуска программы.Для этого создадим следующий обработчик
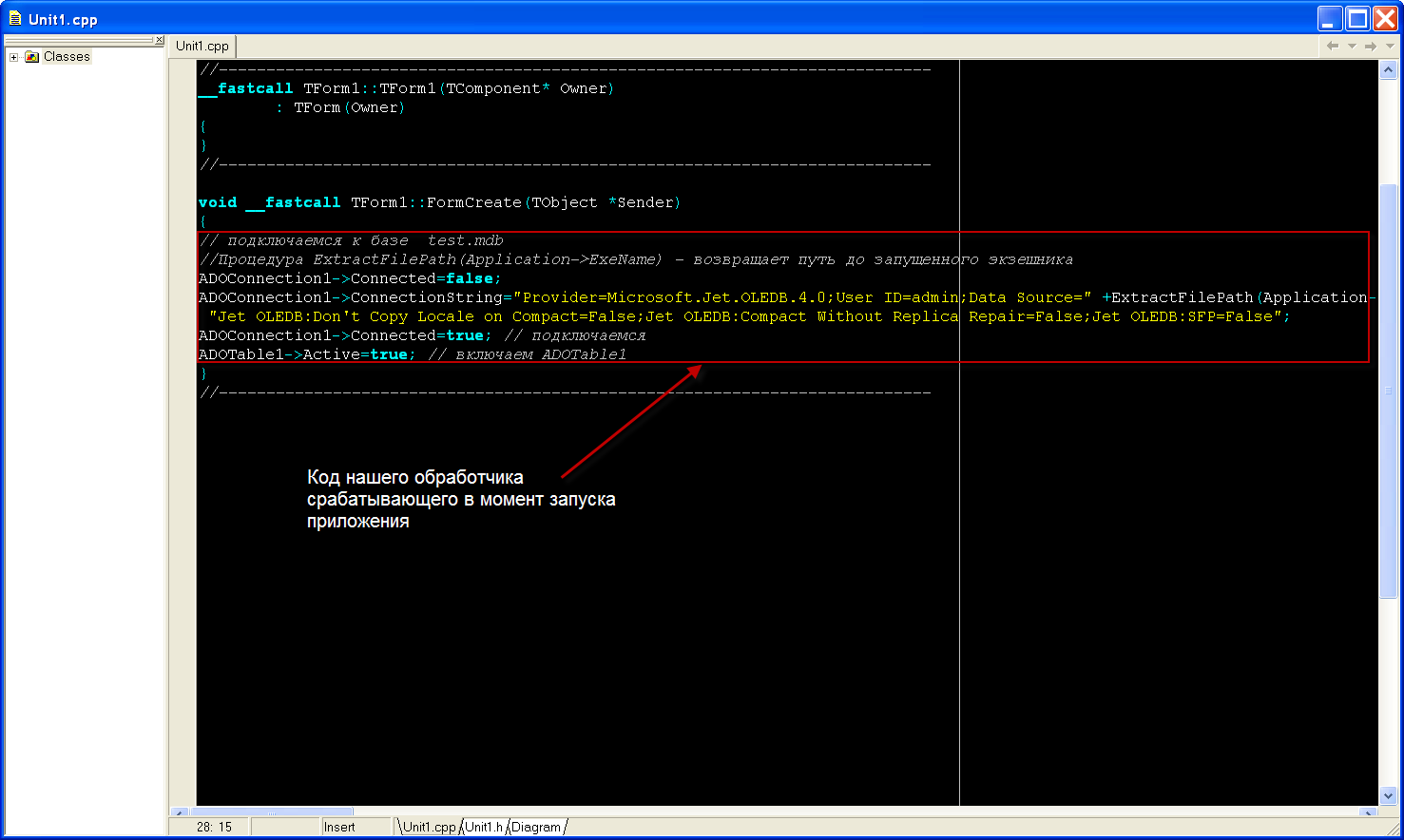
далее нужно в компоненте ADOConnection1 стереть строку ConnectionString
сохраняем, запускаем компиляцию кнопкой F9.
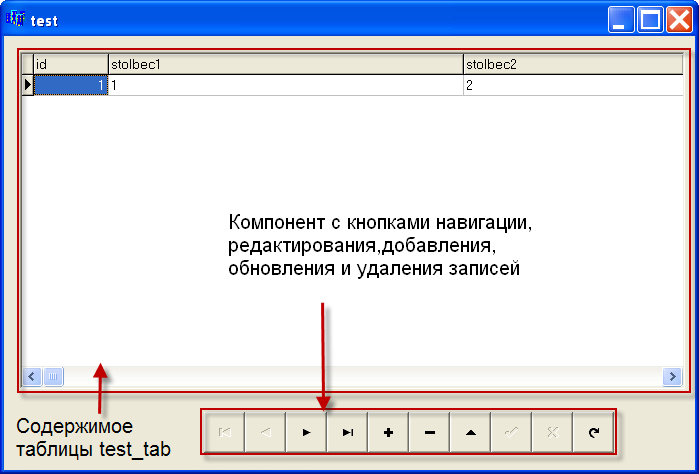
На данный момент у нас получилось приложение взаимодействующее с базой MS Acces посредством технологии ADO, в котором можно производить элементарные действия такие как просмотр, навигацию, редактирование и удаление записей.
Краткое руководство о том как использовать базы Аccess через технологию ADO в С++ Builder.
Первое что нужно сделать это файл будущей базы в MS Access назовем его test.mdb
Далее в режиме конструктора создать там таблицу
создать необходимые толбцы таблици определить их тип и заполнить необходимые параметры
на этом этапе работа в акцесе закончена. Если нужно будет позже поменять структуру таблиц либо создать новые то мы снова вернемся к редактированию test.mdb открыв его в MS Access
Далее Запускаем C++ Builder
Первое что мы делаем это сохраняем проект в туже папку где и наш файл test.mdb
Далее в верхней части интегрированной среды разработки находятся вкладки с компонентами.
Для работы с акцесовской базой нам потребуются следующие компоненты:
1) ADOConnection1 вкладка ADO - данный компонент содержит настройки подключения к БД
2) ADOTable1 вкладка ADO - компонент для операций с содержимым таблиц БД
3) DataSource1 - вкладка Data Access вспомогательный компонент - служит посредником между компонентами для оперирования с данными например ADOTable1 и компонентами для их отображения со вкладки DATA Controls
4) DBGrid1 - вкладка DATA Controls компонент для отображения содержимого таблиц БД
5) DBNavigator1 -вкладка DATA Controls компонент содержит необходимый набор кнопок для навигации по таблице, а таке для добавления, редактирования и удаления записей в таблице.
когда все компоненты на форме перейдем заполнению их параметров.
1) Нужно настроить компонент ADOConnection1, а именно параметр ConnectionString . Для это жмем на кнопку построения строки подключения
Если все ОК. то нажимаем кнопку внизу ОК. если нет то скорее всего нужно посмотреть установлен ли MS Access так как для нормальной работы приложению необходимы его модули. рекомендуется акцесс не ниже 2000.
параметр LoginPromt установить в false что ба каждый раз при первом подключении к БД небыло запроса пароля. Если просит то login: Admin, пароль не заполнять и жмем ОК.
Далее нужно настроить компонент ADOTable1
в нем нужно настроить 3 параметра
1)Красное поле Connection - нужно выбрать ADOConnection1
2)TableName - указать название таблицы из БД - test_tab
3)Вверху параметр Active - выбрать true- параметр включения компонента
Далее нужно настроить компонент DataSource1
нужно указать параметр DataSet ADOTable1
Далее в компонентах DBNavigator1 и DBGrid1 красное поле DataSourse выставить DataSource1
Последний штрих. для того что бы данное приложение работало на другом компьютере или при переносе в другую папку нужно сделать что бы строка подключения в компоненте ADOConnection1 вормировалась в момент запуска программы.Для этого создадим следующий обработчик
далее нужно в компоненте ADOConnection1 стереть строку ConnectionString
сохраняем, запускаем компиляцию кнопкой F9.
На данный момент у нас получилось приложение взаимодействующее с базой MS Acces посредством технологии ADO, в котором можно производить элементарные действия такие как просмотр, навигацию, редактирование и удаление записей.
Вложенные файлы
-
 test.rar 717,27 КБ
310 Скачано
test.rar 717,27 КБ
310 Скачано
icq 336674712
skype fx_mr.bags
skype fx_mr.bags
#5
Mr.Bags
-
- Пользователи ST test (off)
-
- 142 сообщений
живет тут
Опубликовано 04 Март 2010 - 01:39
Для того что бы добавлять значения не используя компонент dbnavigator можно сделать на форме свои кнопки и реализовать соответствующие обработчики.
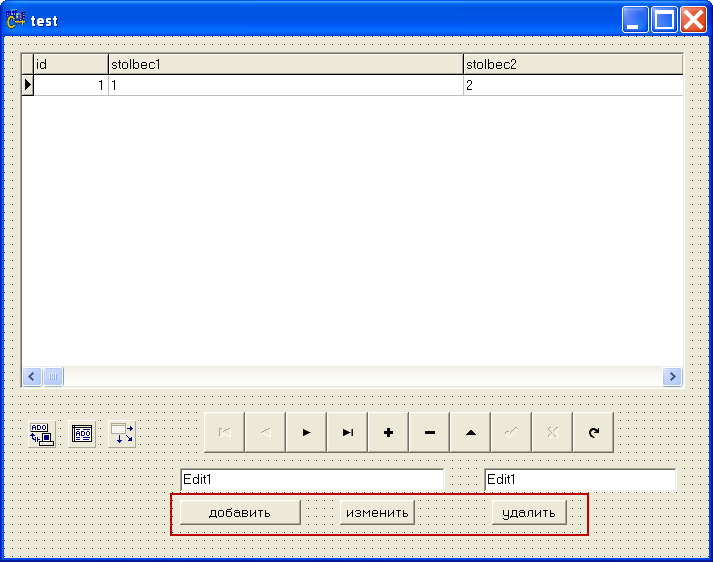
Для манимуляций с записями в данном примере используем свойства и методы компонента ADOTable1
Как правило используются следующие свойства и методы:
ADOTable1->Fields[0][номер столбца таблицы]- хранит значение столбца таблицы текущей записи.
через данное свойтво можно получить значение либо записать его в текущую запись в нужном формате данных.
методы навигации:
ADOTable1->First();- перейти на первую запись в таблице
ADOTable1->Next(); перейти к следующей
ADOTable1->Prior(); вернуться к предыдущей
ADOTable1->Last(); к последней
операции с данными:
ADOTable1->Insert(); // добавляем пустую запись
ADOTable1->Post();// сохраняем изменение в базе
ADOTable1->Delete():// удалить текущую выделенную запись(строку)
ADOTable1->Edit();- перевод строки в режим редактирования
ADOTable1->Eof- возвращает true если достигнута последняя запись- используется в циклах перебора записей для определения последней записи.
Обработчики для кнопки "добавить"
void __fastcall TForm1::Button1Click(TObject *Sender)
{
ADOTable1->Insert(); // добавляем пустую запись
ADOTable1->Fields[0][1]->Text=Edit1->Text;// заполняем в добавленной записи столбец 1
ADOTable1->Fields[0][2]->Text=Edit1->Text;// заполняем в добавленной записи столбец 2
ADOTable1->Post();// сохраняем изменение в базе
}
обработчик кнопки изменить
void __fastcall TForm1::Button2Click(TObject *Sender)
{
ADOTable1->Edit();
ADOTable1->Fields[0][1]->Text=Edit1->Text;// заисываем в текущее поле записи в столбец 1 содержимое едит 1
ADOTable1->Fields[0][2]->Text=Edit1->Text;// заисываем в текущее поле записи в столбец 2 содержимое едит 2
ADOTable1->Post();// сохраняем изменение в базе
}
Обработчик кнопки удалить
void __fastcall TForm1::Button3Click(TObject *Sender)
{
ADOTable1->Delete():// удалить текущую выделенную запись(строку)
}
Для манимуляций с записями в данном примере используем свойства и методы компонента ADOTable1
Как правило используются следующие свойства и методы:
ADOTable1->Fields[0][номер столбца таблицы]- хранит значение столбца таблицы текущей записи.
через данное свойтво можно получить значение либо записать его в текущую запись в нужном формате данных.
методы навигации:
ADOTable1->First();- перейти на первую запись в таблице
ADOTable1->Next(); перейти к следующей
ADOTable1->Prior(); вернуться к предыдущей
ADOTable1->Last(); к последней
операции с данными:
ADOTable1->Insert(); // добавляем пустую запись
ADOTable1->Post();// сохраняем изменение в базе
ADOTable1->Delete():// удалить текущую выделенную запись(строку)
ADOTable1->Edit();- перевод строки в режим редактирования
ADOTable1->Eof- возвращает true если достигнута последняя запись- используется в циклах перебора записей для определения последней записи.
Обработчики для кнопки "добавить"
void __fastcall TForm1::Button1Click(TObject *Sender)
{
ADOTable1->Insert(); // добавляем пустую запись
ADOTable1->Fields[0][1]->Text=Edit1->Text;// заполняем в добавленной записи столбец 1
ADOTable1->Fields[0][2]->Text=Edit1->Text;// заполняем в добавленной записи столбец 2
ADOTable1->Post();// сохраняем изменение в базе
}
обработчик кнопки изменить
void __fastcall TForm1::Button2Click(TObject *Sender)
{
ADOTable1->Edit();
ADOTable1->Fields[0][1]->Text=Edit1->Text;// заисываем в текущее поле записи в столбец 1 содержимое едит 1
ADOTable1->Fields[0][2]->Text=Edit1->Text;// заисываем в текущее поле записи в столбец 2 содержимое едит 2
ADOTable1->Post();// сохраняем изменение в базе
}
Обработчик кнопки удалить
void __fastcall TForm1::Button3Click(TObject *Sender)
{
ADOTable1->Delete():// удалить текущую выделенную запись(строку)
}
icq 336674712
skype fx_mr.bags
skype fx_mr.bags







Посетителей, читающих эту тему: 0
0 пользователей, 0 гостей, 0 анонимных пользователей



